Torch Points3D - A unifying framework for deep learning on point clouds
This is a joint publication with Thomas Chaton and Loic Landrieu.
Github: https://github.com/nicolas-chaulet/torch-points3d
With the rise of ever more affordable LiDAR sensors and more efficient photogrammetry algorithms, 3D point cloud data have become easier than ever to acquire. The deep learning community has embraced this trend by developing new network architectures to perform various tasks on 3D data. The sheer volume of possibilities (data layouts, data augmentation, convolution strategies, etc…) is such that it can be time-consuming to find the best fit for your data or problem.
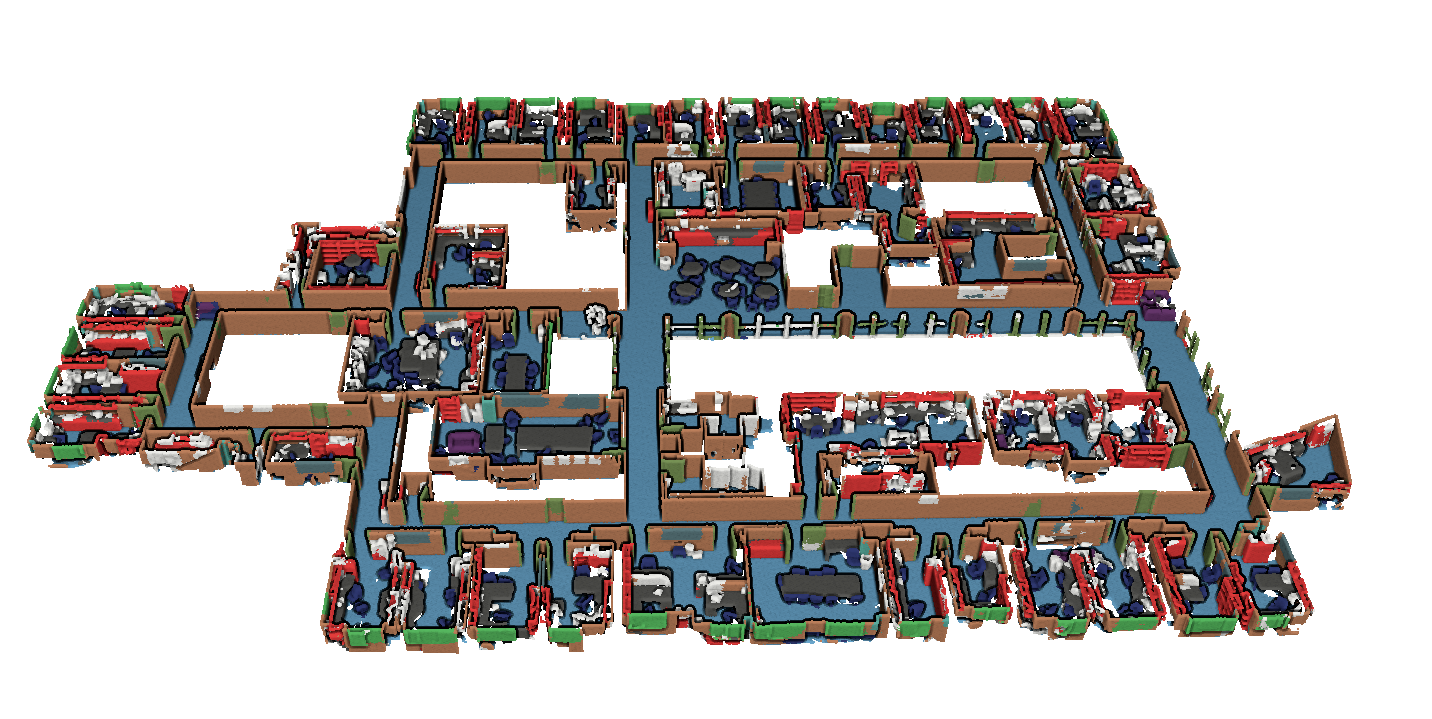
Semantic segmentation output obtained with KPConv
Our framework, Torch Points3D, was developed to become the torchvision of point cloud data: a flexible and extensible framework for researchers and engineers alike working on point cloud-based machine vision. Ever wondered how KPConv could perform for point cloud registration? Or PointNet++ for object detection with random sampling instead of furthest point sampling as suggest in RandLa-Net? With Torch Points3D you can now try multiple state-of-the-art backbone models in just a few lines of code.
After a quick recap about the specificity of point clouds, we will present the following aspects of Torch Points3D:
- Optimized data layouts for point cloud data
- Native integration of many academic datasets
- Fast and robust data processing and data augmentation
- Tested convolution kernels for a range of sparse and point-based architectures
- Easy-to-use API for accessing datasets, data transforms, and preconfigured models
We provide training scripts with useful features such as model checkpointing, logging to Tensorboard and Weight and Biases, easy configuration of hyper parameters with Facebook’s Hydra, and more. You can also use our core components with your favourite training framework such as PyTorchLightning, for example.
We hope you enjoy the read! We are open to your feedback and contributions here.
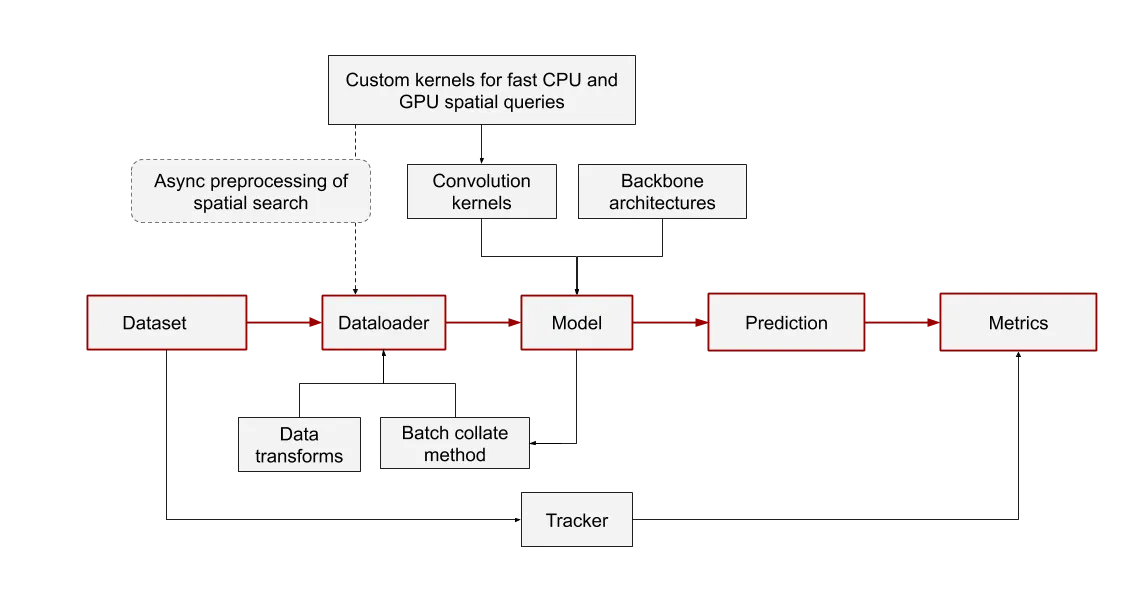
System diagram of Torch Points3D, data flow highlighted in red
Why are point clouds so special?
Challenges around 3D sparse point clouds are broadly described in the research literature, we will just mention a few key differences between 3D point clouds and 2D images:
- Each point cloud can have a different number of points even if they have the same spatial resolution. This aspect makes constituting homogeneous batches more difficult for point clouds than images.
- LiDAR sensors capture surfaces in a 3-dimensional world, therefore the data is sparse by nature. Cameras, on the other hand, produce dense acquisitions.
- The density of points varies within the same point cloud, therefore some points may have many close neighbours to derive precise geometric information while others may be isolated.
- Point clouds are invariant under re-indexing of the indices of their points, while the indices of pixels are inherently linked to their coordinates. This means that the processing techniques used to handle point clouds must also be permutation-invariant.
Point cloud data and data layouts
There are two ways to assemble heterogeneous batches. The first is to make all elements in the batch the same size by subsampling and oversampling, and collate them in a new batch dimension (just like you would collate images). We will refer to this approach as dense batching. Alternatively, you can directly collate the samples in the point’s dimension and keep track of the number of points in each sample. We will refer to this approach as packed batching.
Dense batching is used by the official implementations PointNet++, Relation-Shape CNN, and similar architectures. The main benefit, beyond its simplicity of implementation, is that it can leverage hardware optimizations related to classic 2D convolutions. The downside is that some samples may have many duplicate points while others have been heavily subsampled, discarding information. The number of points per sample must be chosen carefully. On the other hand, more recent models such as KPConv or Minkowski Engine work with packed batching, which removes the need to sample the elements in the batch, and in some cases can significantly reduce the memory requirements. The good news is that we support both data formats, and our data loader can easily switch from one to the other.
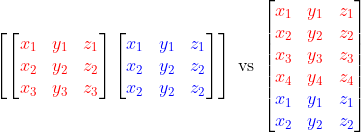
Dense batch collate on the left and packed batch collate on the right, for the same two point clouds (red and blue).
Core datasets supported
The framework provides easy access to several datasets widely used by the community. At the moment we support the following datasets:
To use Torch Points3D datasets within your own framework you can simply write:
>>> dataset = ShapeNet("data_folder", split="train")
>>> dataset[0]
Data(pos=[5023, 3], x=[5023, 3], y=[5023])
All our datasets produce Data objects, simple structures holding tensors for the points’ positions and features data.pos and data.x respectively (they are actually PyTorch Geometric Data objects). Here pos is the raw 3D position and x is the normal vector at each point. During training, Data objects also contain the labels y and any other information that might be required by a specific model or task.
Data processing pipeline
The data processing pipeline is a key component to any deep learning model. PyTorch Geometric already provides a number of useful transform functions that we have enriched with additional 3D-specific features; you can find the list at this link. In addition to this wide range of data transforms, we have also added helpers to directly instantiate data pipelines from yaml configuration files. This makes the data augmentation a transparent process, which in turn improves reproducibility and makes adapting existing models easier. A typical configuration file looks like this:
data:
class: shapenet.ShapeNetDataset
task: segmentation
dataroot: data
normal: True # Use normal vectors as features
first_subsampling: 0.02 # Grid size of the input data
information
pre_transforms: # Offline transforms
- transform: NormalizeScale
- transform: GridSampling
params:
size: ${data.first_subsampling}
train_transforms: # Data augmentation pipeline
- transform: RandomNoise
params:
sigma: 0.01
clip: 0.05
- transform: RandomScaleAnisotropic
params:
scales: [0.9,1.1]
Convolutions kernels
Most point-based convolution networks borrow the common encoder/decoder idea (or encoder only). An encoder operates on a dense point cloud, which is iteratively decimated after each layer or group of layers as we go deeper. The points themselves support feature vectors, and going from one layer to the next usually entails two steps:
- downsampling the point cloud;
- for each point in the downsampled point cloud, computing a feature vector based on the features of its neighbours in the previous point cloud.
In short, the deeper in the network, the fewer the points — but the richer their associated features. Typical encoding process for point clouds. Each lamp represents the point cloud coming out of a given layer and the red sphere highlights which points from the previous layer are used to build the new feature vector (image credit: Hugues Thomas).
Our framework supports three interchangeable sampling strategies: random sampling, furthest point sampling, and grid sampling. For neighbour search, most networks use neighbourhoods with a fixed radius or k-nearest-neighbour.
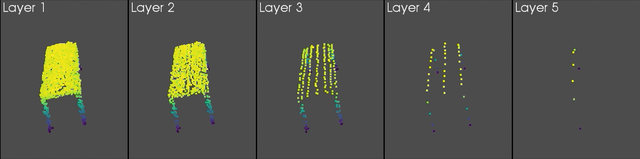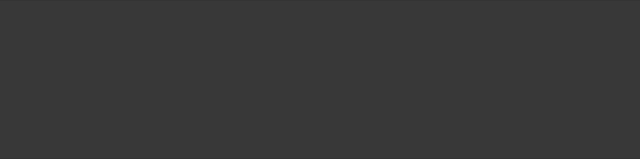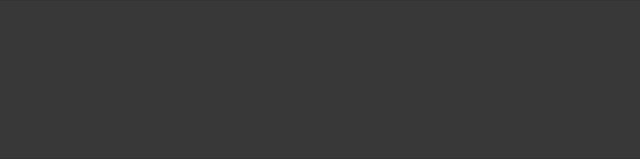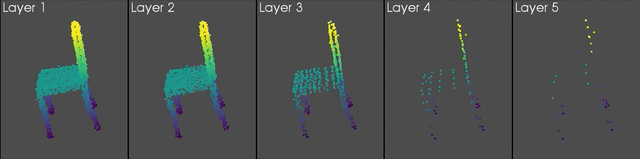
Various levels of grid sampling in a KPConv model.
Torch Points3D has been created with modularity in mind. We complement the sampling strategies and neighbour search algorithms with convolution kernels for a wide range of models as stand-alone modules that can be included within your own architecture. As of today, the following modules are available:
- Pointnet++
- Relation-Shape CNN
- KPConv
- Minkowski Engine (through the official python package)
For example, one can create a strided KPConv convolution block as follows:
>>> import torch_points3d.modules.KPConv.blocks as kpconv_modules
>>> kpconv_layer = kpconv_modules.SimpleBlock(
down_conv_nn = [64,128],
grid_size=0.1,
prev_grid_size=0.05
)>>> kpconv_layer
SimpleBlock(
GridSampling(grid_size=0.1),
RadiusNeighbourFinder(radius=0.125),
(kp_conv): KPConvLayer(InF: 64, OutF: 128, kernel_pts: 15, radius: 0.0),
(bn): BatchNorm1d(128, eps=1e-05, momentum=0.02),
(activation): LeakyReLU(negative_slope=0.1)
)
Our framework takes care of all the details under the hood. For example, it sets appropriate parameters for the convolution kernel and the grid sampling operator corresponding to this strided convolution.
Those core convolution schemes have all been validated on the semantic segmentation task and published results have been reproduced in close collaboration with the respective authors. We plan on continuously adding newer convolution schemes as they are released.
API
We have started exposing part of the framework through an easy-to-use API. For now, the API supports:
- common data transforms for doing data augmentation on point clouds
- common datasets for segmentation tasks with batch collate functions and robust metric trackers
- backbone models based on a Unet architecture for KPConv, Pointnet++ and Relation-Shape CNN

Please refer to https://torch-points3d.readthedocs.io for an up to date documentation of the API or take a look at our example notebooks that can be run on colab:
Final words
Torch Points3D is an evolving framework with new features added on a daily basis, some upcoming features are:
- Integration of newer architecture such as RandLa-Net;
- Integration of more tasks such as point cloud registration, instance segmentation, primitive fitting, outlier removal, point cloud completion and more;
- Pre-trained models directly accessible through our model API.
We also would like to warmly thank everyone who has been involved in the project and in particular Sofiane Horache, Hugues Thomas, Tristan Heywood and the R&D team from Fujitsu Laboratories of Europe.
References
Models
- PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
- KPConv: Flexible and Deformable Convolution for Point Clouds
- Relation-Shape Convolutional Neural Network for Point Cloud Analysis
- 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks
- RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
Datasets
- ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
- Joint 2D-3D-Semantic Data for Indoor Scene Understanding
- ShapeNet: An Information-Rich 3D Model Repository
- 3D ShapeNets: A Deep Representation for Volumetric Shapes
- 3DMatch: Learning the Matching of Local 3D Geometry in Range Scans